Andmekool #4: Kuidas moodustatakse uuringute valimid?
Statistika tegemise enim ressursse nõudev etapp on andmekogumine. Kui algandmeid on võimalik saada ainult küsitlemise teel, siis on kaks võimalust: kas küsitletakse kõiki üldkogumit moodustavaid objekte või piirdutakse ainult osaga neist. Esimesel juhul räägitakse kõiksest uuringust, teisel juhul valikuuringust.
Kuidas kogutakse Eesti elu puudutavaid andmed ja mida nendega tehakse? Kuidas saab rahvaloendusel kõik Eesti inimesed üles lugeda, kui minu ukse taga ei käinud keegi? Kuidas minu elu sellest paremaks muutub, kui SKP-d arvutatakse? Statistikaameti blogisari „Andmekool“ tutvustab ameti tööd ja statistika tegemist lähemalt!
Valikuuring või kõikne uuring? Mis on valim?
Statistika tegemise enim ressursse nõudev etapp on andmekogumine. Kui algandmeid on võimalik saada ainult küsitlemise teel, siis on kaks võimalust: kas küsitletakse kõiki üldkogumit moodustavaid objekte või piirdutakse ainult osaga neist. Esimesel juhul räägitakse kõiksest uuringust, teisel juhul valikuuringust.

Kõikse uuringu klassikaline näide on traditsiooniline rahvaloendus, kus küsitlejad peavad jõudma iga isiku juurde. Ettevõtlusstatistika uuringud koosnevad aga reeglina kahest osast. Kõiki suuri ettevõtteid küsitletakse kindlasti, ülejäänutest võetakse juhuslik valim. Piir suurte ja väikeste ettevõtete vahel määratakse töötajate arvu järgi. Olenevalt uuringust algab suur ettevõte kas 20-st või 50-st töötajast.
Teist andmekogumise viisi nimetame valikuuringuks. Sel juhul küsitletakse üldkogumist ainult üht osa – tavaliselt suhteliselt väikest osa –mida nimetatakse valimiks. Valimilt saadud tulemused laiendatakse üldkogumile. Ettevõtlusstatistika uuringud on tavaliselt kombineeritud, st koosnevad kõiksest osast ja valikuuringust. On ilmne, et valikuuringu tulemused sisaldavad valimi juhuslikkusest ja osalisusest tingitud viga – valimiviga, mis teatud tingimustele vastavate valikuuringute puhul on mõõdetav. Siis nimetatakse seda standardveaks.
Kuidas valim saadakse?
Ülal kirjeldatu järgi võetakse kõikse uuringu valimisse kõik üldkogumit moodustavad füüsilised või juriidilised isikud. Kõikne valim on seega üldkogum ise ja kuna tegelikult midagi ei valita, siis puudub ka valimiviga. Valikuuringus, nagu nimigi ütleb, küsitletakse üldkogumist ainult osa – valimit. Valimeid on kaht tüüpi: ekspertvalimid ja tõenäosuslikud valimid. Ekspertvalimi paneb kokku kogemustega valimiekspert. Valim püütakse saada võimalikult sarnane üldkogumiga, et see oleks üldkogumit esindav. Kahjuks ei saa ekspertvalimi puhul mõõta, kui palju üks või teine valim üldkogumit esindab ja uuringu lõpus ei ole teada, kui hästi üldkogumi valimi põhjal hinnatud näitajad üldkogumit iseloomustavad. Seetõttu kasutab statistikaamet uuringutes tõenäosuslikku valimit.
Tõenäosusliku valimi võtmisel on eksperdil ja esindavusel teine tähendus. Tõenäosusliku valimi korral on „eksperdiks“ juhuslik protseduur, mille valib ja käivitab matemaatilise statistika asjatundja. Tõenäosusliku valimi puhul peab olema täidetud kaks tingimust: 1) üldkogumi igal objektil peab olema võimalus valimisse sattuda ning 2) valimisse sattumise tõenäosus peab olema teada ja võib olla mistahes arv 0 ja 1 vahel, välja arvatud 0. Lihtsaim tõenäosuslik valim on lihtne juhuvalim ehk loterii. Kui üldkogumi objektide arv on N ja loosirattast võetakse üksteise järel välja n objekti, kusjuures ühtki väljatõmmatutest tagasi ei panda, on iga objekti valimisse sattumise tõenäosus n/N . Selle tõenäosuse pöördarvu nimetatakse objekti kaaluks ja lihtsa juhusliku valimi puhul on iga objekti kaal N/n.
Lihtsat juhuvalimit puhtal kujul kasutatakse harva. Tavaliselt jagatakse üldkogum enne valimi võtmist ühisosata osakogumiteks, mida nimetatakse kihtideks, ja uuringu valim moodustatakse kihtidest tõmmatud osavalimitest. Olgu sellise valimi nimi lihtne kihtjuhuvalim.
Uuringu eesmärgist lähtuvalt kasutatakse praktikas tihti lihtsast (kiht)juhuvalimist erinevaid tõenäosuslikke valimeid. Tegelikult võib tõenäosusliku valimi võtta nn „rätsepatööna“, omistades üldkogumi igale objektile individuaalse valimisse sattumise tõenäosuse. Kui on teada, kuidas tõenäosuslik valim võeti, saab hinnata üldkogumi mistahes näitajat koos vastava standardveaga.
Kui valimilt andmed kogutud, mis edasi?
Tõenäosuslikus valimis esindab iga valimisse tõmmatud objekt iseennast ja lisaks veel teatud hulka valimisse mittesattunud objekte. Tõenäosuslik valim esindab üldkogumit, küsimus on ainult kui hästi. Kui näiteks iga sajas tööeas isik loositakse valimisse, siis on mõistlik mõelda nii, et ta esindab iseennast ja veel 99 tööeas isikut ehk tal on üldkogumis 99 klooni. Kui valimisse sattunud isik on töötu, eeldatakse vaikimisi, et lisaks temale on üldkogumis veel 99 töötut. Kui valimi isik on tööga hõivatud, siis on üldkogumis eeldatavalt veel 99 tööga hõivatut. Kui iga kümnes ettevõte tõmmatakse valimisse, siis igaüks neist esindab lisaks iseendale vee üheksat ettevõtet. Kui mingi valimisse sattunud ettevõtte aastakäive on näiteks 200 000 eurot, laiendatakse see ülejäänud üheksale ehk vaadeldava kümne ettevõtte kogukäibe hinnang on 10 × 200 000 = 2 000 000.
Tegelikkus on muidugi teistsugune, kuid tõenäosusliku valimi puhul on võimalik mõõta eksimise suurust ehk valimiviga.
Kuidas leida valimiviga ja mida sellest järeldada saab?
Selle järgi, kuidas tõenäosuslik valim võeti, arvutatakse valimi objektidele kaalud (ehk laiendustegurid). Valimilt kogutud andmed korrutatakse laiendusteguriga ja seejärel arvutatakse laiendatud andmete põhjal üldkogumi parameetrite hinnangud – kogusummad, keskmised, osatähtsused, mis kõik sisaldavad valimiviga. Matemaatiline statistika annab teaduslikult põhjendatud tööriistad nende vigade hindamiseks ning vastavad arvutiprogrammid on kirjutatud ja kättesaadavad üle maailma.
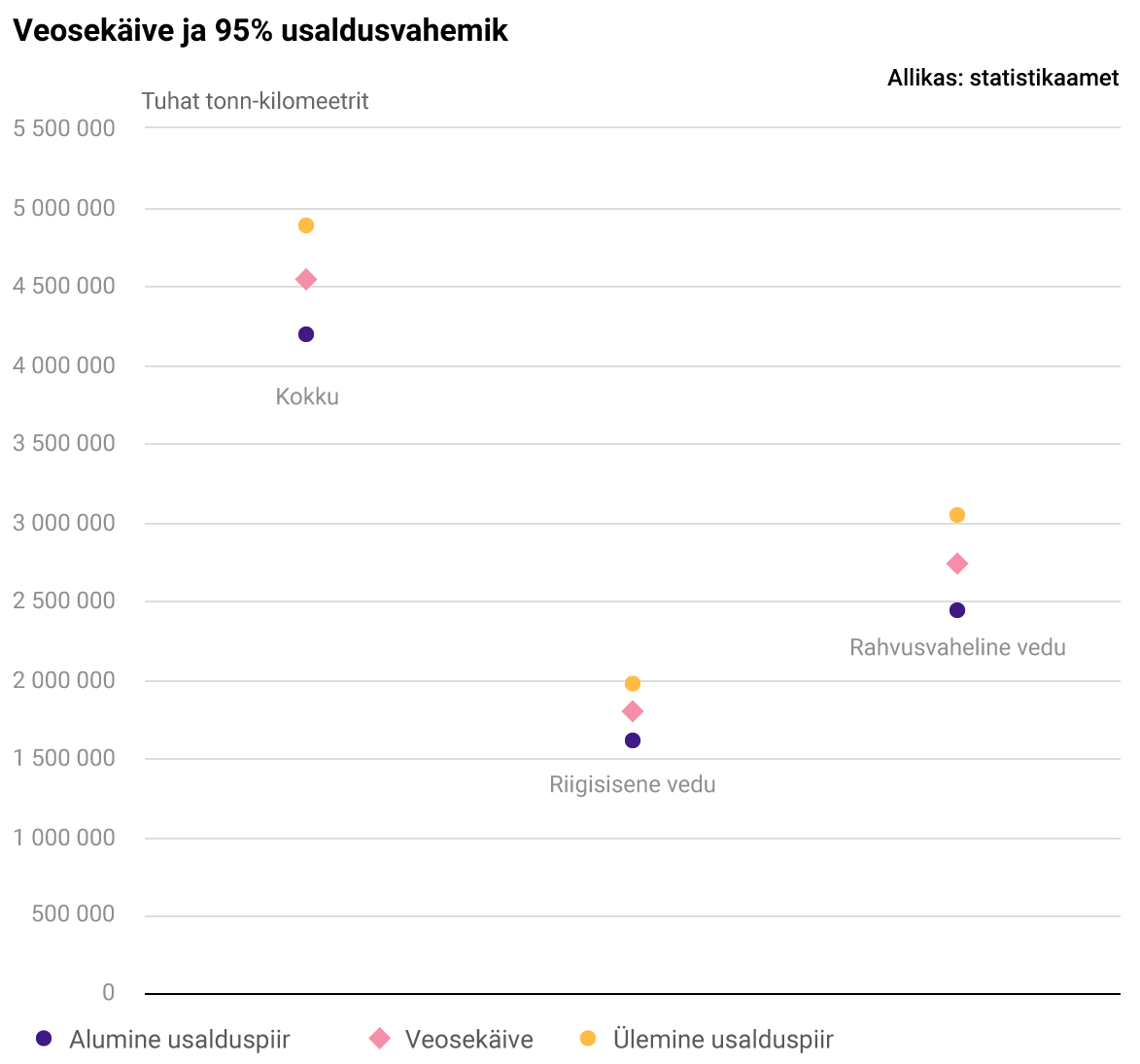
| 2022 | Veosekäive, tuhat tonn-kilomeetrit | Veosekäibe standardviga, tuhat tonn-kilomeetrit | Veosekäibe suhteline standardviga, % |
|---|---|---|---|
| Riigisisene ja rahvusvaheline vedu kokku | 4 540 060 | 175 195 | 4 |
| Riigisisene vedu | 1 796 489 | 92 675 | 5 |
| Rahvusvaheline vedu | 2 743 571 | 155 044 | 6 |
Uuringu üldkogumi moodustasid 2022. aastal sõitnud ja kaupa vedanud autod ning uuringu eesmärk oli hinnata mitmesuguseid kaubaveonäitajaid, sh veosekäivet.
Veosekäive on saadud valimisse sattunud autode algandmete laiendamisel, st algandmete korrutamisel kaaluga. Veosekäibe standardviga on arvutatud vastavate valemite järgi tarkvara R paketi Survey abil ja veosekäibe suhteline standardviga on veosekäibe standardvea ja veosekäibe suhe protsentides. Mida väiksem on suhteline standardviga, seda parem on hinnangu kvaliteet.
Kuigi veosekäive on avaldatud tuhande tonn-kilomeetri täpsusega, ei saa antud juhul rohkem öelda, kui et tegelikku 2022. aasta kõigi riigisiseste ja rahvusvaheliste vedude veosekäivet kokku katab 95% tõenäosusega vahemikus 4 540 060 ± 1,96 × 175 195 tonn-kilomeetrit ehk väljakirjutatuna vahemikus 4 196 678 kuni 4 883 442 tonn-kilomeetrit. Arv 1,96 ja tõenäosus 95% kuuluvad kokku ja kirjeldatud vahemikku nimetatakse koguveosekäibe 95% usaldusvahemikuks. Täpselt samuti saab arvutada usaldusvahemikud ka riigisisesele veosekäibele ja rahvusvahelisele veosekäibele eraldi.
Kokkuvõte
Valikuuringu meetod on võimaldanud erinevates statistikavaldkondades pikka aega andmekogumise mahtu oluliselt vähendada. 19. sajandi lõpus võeti kasutusele ekspertvalimid, möödunud aastasaja kolmekümnendatel tõenäosuslikud valimid. Tänapäeva e-maailmas võimsa arvutustehnika olemasolul on tekkinud palju muid andmekogumismeetodeid, mis asendavad küsitlemise ning ka valikuuring kui meetod liigub kunagi ajalukku.