Statistikaameti andmekool #7: Andmed korda, 1, 2, 3
Üha rohkem räägitakse sellest, et andmete abil saab teha paremaid ja targemaid otsuseid. Selleks peavad andmed aga korras olema. Kuidas selle igapäevase väljakutsega alustada?
Kuidas kogutakse Eesti elu puudutavaid andmed ja mida nendega tehakse? Kuidas saab rahvaloendusel kõik Eesti inimesed üles lugeda, kui minu ukse taga ei käinud keegi? Kuidas minu elu sellest paremaks muutub, kui SKP-d arvutatakse? Statistikaameti blogisari „Andmekool“ tutvustab ameti tööd ja statistika tegemist lähemalt!
Üha rohkem räägitakse sellest, et andmete abil saab teha paremaid ja targemaid otsuseid. Selleks peavad andmed aga korras olema. Valdkonda, mis keskendub andmetega „toimetamisele“ nimetatakse andmehalduseks. Tõhusast andmehaldusest on kasu nii asutusele endale kui ka teistele organisatsioonidele, kellega andmeid jagatakse. Nende seas on ka statistikaamet, kes teeb statistikat Eesti elu puudutavate näitajate kohta – nii ise andmeid kogudes kui ka riiklikele andmekogudele tuginedes. Statistikaamet on ühtlasi andmehalduse koordineerija Eestis.
Andmete korrastamine on igapäevane väljakutse. Kuidas sellega alustada? Kas teha suurpuhastus ja talgud või hakata nokitsema ühest nurgast? Kuna on üsna tavaline, et täpselt ei ole selge ei see, kuidas ja kust alustada ega ka see, kuhu välja jõuda, siis vähemasti koosoleku, et asja üle arutada, oskab kokku kutsuda igaüks. Seejärel ei toimu mingit „1-2-3 korras!“ toimetamist, vaid esimene, teine ja kolmas koosolek. Kuidas seda mitte kuhugi välja viivat lähenemist vältida?
Selle kirjatüki eesmärk on säästa mõnel määral vaeva, kui andmete korrastamine on juba plaani võetud. Üks on selge – lihtsat ja automatiseeritavat lahendust ei ole. Kuhugi koopia tegemine on analoogne kurikuulsa arhiivikorrastusviisiga „topime paberid kartulikottidesse ja kotid viime keldrisse“. Sissevaade andmestikesse on paratamatu. Õige viis on mõistlike andmehulkadega kindlate kriteeriumite alusel töötamine.
Möödapääsmatu on kokku leppida, mis on andmed ja mis on kord. Andmed võivad olla nii andmekogudes ja infosüsteemides olevad andmed kui ka failid jagatud ketastel, kasutajate n-ö oma arvutis kui ka füüsilistel andmekandjatel, nagu CD, mälupulk jms. Sellisel juhul on andmed konkreetsed failid arvutite kõvaketastel ja füüsilistel andmekandjatel olev informatsioon. Aga kuna failide tüüpe ja vorminguid on tohutult, siis taas on mingi eristus oluline.
„Kord, see on süsteem,“ õpetas juba Toots Kiirele. Või jah, tal oli see vastupidi. Igal juhul on see teatavate kriteeriumite alusel andmete süstematiseerimine. Siin aga lihtsus lõpeb. Siiski, nagu H. Runnel kirjutas: „… mitte ehmuda sõnnikuveost“, et liigpalju koosolekuid ei jääkski „ainsaks vägiteoks“ – andmemaa palge saab ilusaks pühkida!
Korra loomisel ei ole vaja teha vahet, kas tegu on andmete, info, teabe või digidokumentidega. See on kõik üks digitaalne aines, info- või andmevara, mis tuleb kas organiseerida või teha sellele n-ö inventuur (varade ehk andmestike nimekiri, mida sageli nimetatakse kataloogiks). Mis on korrastatav tükk? Praktiliselt on kasulik neid rühmitada kolmeks: 1) relatsioonilised andmebaasid, 2) failid jagatud ketastel ja kasutaja arvutis, mis on seotud töötaja või asutuse töödega (st ei ole programmide failid, süsteemsed failid jms), 3) muud infovarad. Viimased on küll veidi raskesti piiritletavad, aga nendena tuleks käsitleda sellistes rakendustes olevat infot, mida töös kasutatakse. Nendeks on töötajate postkastid ja veebilehed, kus töine info (nagu Confluence, Jira või SharePoint). Samuti sise- ja välisveeb ning Teams, Meet ja muud sellised vidinad.
Korrastamist tuleb alustada andmebaasidest ja failidest. Neli kindlat sammu on pea kõigile jõukohased ja tagavad minimaalse edu. Oluline on see, et andmete korrastamine ja kirjeldamine peavad käima koos. Kirjeldus aitab andmed hiljem üles leida. Kirjeldus on metaandmed ehk andmed andmete kohta.
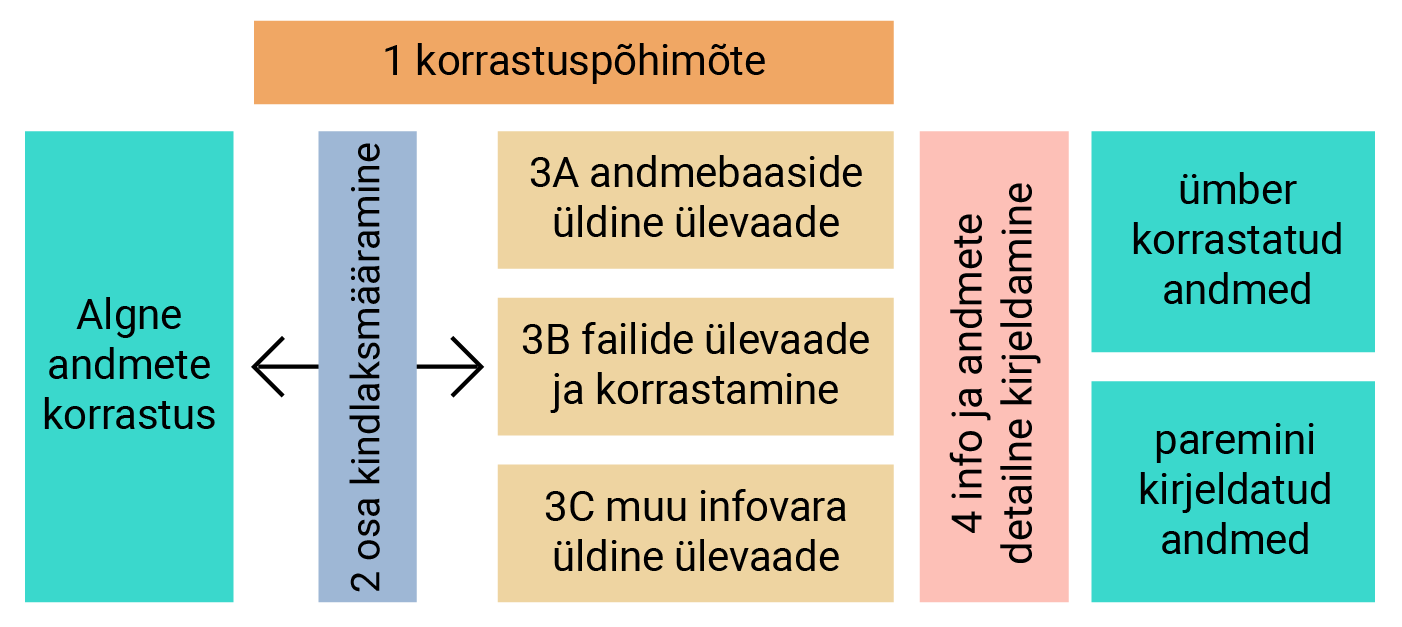
SAMM 1 – korrastamispõhimõte
Failide puhul on korrastamine nende otstarbekas jagamine kaustadesse (folderitesse), vabanemine koopiatest ja kavanditest. Heal juhul ka nimetamisreeglite määramine. Failidele metaandmete lisamine käib juba kirjeldamise alla (samm 4). Oluline on säilitada mõistlikul määral originaalne kord. Näiteks failide organiseerimine suuruse, loomise või viimase kasutamise või vormingu järgi ei pruugi olla õige. Faili tekkekonteksti ei ole vaja mõtlematult ära kaotada.
Andmebaaside osas piisab andmebaasi ning vahel baasides olevate skeemide ja tabelite nimekirjast. See nimekiri on tehniline andmekataloog. Seega on andmebaaside korrastus eelkõige ülevaade neis olevatest andmetest. Siiski on oluline aspekt, et andmebaasi paljud andmed saadakse muudest allikatest ning neist ka võetakse andmeid. See tähendab, et korrastus on seotud andmete protsessiga. Seda protsessi andmete loomisest ja saamisest kuni nende vajaliku esmase kasutuse lõppemiseni nimetatakse andmete elukäiguks, milles andmed läbivad etappe. Etapid on vaja selgeks teha ning määrata neist kõige olulisem. Tavaliselt on need kas alguse või lõpuga seotud etapid.
Muude infovarade osas tuleb määrata nende liigid ning koostada liikide kaupa nimekirjad. Näiteks kõik SharePointi saidid, kõik kasutajate postkastid jne.
SAMM 2 – osa kindlaksmääramine
Kui suurem pilt andmete tüüpidest on selge, tuleb kindlaks määrata, millega tegeleda esimeses järjekorras. Kuigi teooria kirjeldab tavaliselt, et info või andmete väärtuse terviklikuks hindamiseks on kõige õigem vaadata tervet protsessi, siis digitaalse ainesega töötamise praktikas on seda raske teha. Seega ei tuleks alustada protsessidest, millega info ja andmed on seotud, vaid ainese osast. Andmebaaside osas on see samm taas lihtne – tuleb hakata andmebaaside kaupa kirjeldama.
Kui käsile on võetud failide korrastamine, tuleb alustada mingist osast jagatud kettast. Esiteks tuleb veenduda, et on olemas juurdepääs – kõik failid on näha. Edasi tuleb otsustada, kas ketta struktuuri osa või muul alusel, millise osaga tegeleda. Näiteks võib luua n-ö kollektsiooni mingit tüüpi failidest. Selline lähenemine on õige siis, kui tekkiv kollektsioon on eraldi vaadeldavana kasutatav. Näiteks võib selliselt organiseerida uuringute ja analüüside lõpptulemeid või teisest kasutust leidvaid analüütilist sisu omavaid faile. Sageli nimetatakse selliselt korrastatud kogumit repositooriumiks.
SAMM 3A (andmebaas/andmekogu) – üldine kirjeldus
Andmebaasi või andmekogu kohta, st andmestiku kohta, millel on andmemudel, tuleb teha üldine kirjeldus. Tehtud kirjeldustest moodustub nimekiri või kataloog, lihtsamalt öeldes tabel. Kataloogitava üldine kirjeldus on rida kirjelduselemente, nagu pealkiri, koostamise aeg, omanik või vastutaja. Kirjelduselementide täielik soovitatav nimekiri on esitatud kirjeldusstandardis.
Andmebaasi pealkiri peab avama selle sisu. Kui andmekogude puhul võib olla olemas ametlik nimetus, siis paljudel muudel juhtudel on vaja andmestikud pealkirjastada. Hästi koostatud pealkirjast on väga palju abi!
SAMM 3B (failid jagatud ketastel) – üldine kirjeldus ja organiseerimine
Failide korrastamine ja kirjeldamine on omavahel seotud. Esmalt tuleb luua uus kaustade struktuur ja selgeks teha, kuidas kaustu nimetada. See peab arvestama nii protsesside kui ka struktuuriga, kuidas failid seni on ja kuidas peaks olema. Uues struktuuris on tähtsad nii ülevaatlikkus sisust kui ka juurdepääsude haldus. Failide ümbernimetamine on õige ainult siis, kui lisatakse ka muu kirjeldus: et fail oleks ka hiljem leitav. Nii on mõistlik teha kollektsiooni ja repositooriumi loomisel. Asjatut failide ükshaaval ümbernimetamist tuleks vältida.
Oluline on ebavajalike koopiate ja kavandite ning väärtusetute failide hävitamine. Mitmekordsete koopiate kindlakstegemiseks on olemas tehnilised abivahendid. Õige ongi failide korrastamiseks kasutada rohkete funktsionaalsustega failihaldustarkvara.
Kui korrastamisel on suurem tükk, on mõistlik teha uutesse kaustadesse koopiad ja jätta vana alles. Seda selleks, et kui on vaja korrastust muuta, siis saab vana juurde tagasi pöörduda. Kui on piisavalt selge, et uus struktuur sobib, võib vana hakata kustutama. Faile, mida uude struktuuri ei kanta, tuleb enne lõplikku kustutamist hoida eraldi kohas ning kustutada need kõige lõpus.
SAMM 3C (muud infovarad) – üldine kirjeldus
Muude infovarade korrastamise ja kirjeldamise korral tuleb, nagu andmekogudegi puhul, luua nimekiri või kataloog. Ka nende puhul on oluline pealkirjade panek. Ümberkorrastamine toimub nende puhul eelkõige aktiivse ja arhiivi osa eristamisel, kui mitteaktiivsed osas kantakse arhiivi osasse.
SAMM 4 – andmete kirjeldamine
Nii andmebaaside, osade failide kui ka mõne infovara korrastamisel on vaja kirjeldada nende sisu ja struktuuri. Kõige kindlamalt on seda vaja teha andmebaaside ja tabelitega. Teie juhus, kus selline kirjeldamine on oluline, on CSV-vormingus failid. Need on sageli kasutusel mingis analüüsi või statistika tegemise faasis. See kirjeldamine on töömahukas ning kuna näiteks Exceli faile on tavaliselt väga palju, on vaja teha kindlaks, millised neist vajaks sisu ja struktuuri kirjeldamist. See tähendab, millised on väärtuslikud.
Võtame kirjeldamise näiteks tabeli. Selle veerud ja read omavad tähendust, mis tuleb veeru haaval kirjeldada: panna veerule pealkiri, teha kindlaks selle tüüp jms. Täpne kirjeldamine on töömahukas ja sellest on täpsemalt juttu andmekirjelduse juhises. Read omavad ka tähendust – need võivad olla üksikute faktide kirjed või ka arvulised kokkuvõtted nagu statistilised väljundid.
Detailne andmete kirjeldamine eeldab seda võimaldava rakenduse olemasolu. Riik on andmekogude kirjelduste koostamiseks loonud rakenduse RIHAKE, mis on tasuta kasutatav (vt koodivaramu). Kui on soov andmestikud, aga mitte aktiivses kasutuses olevad andmebaasid korrastada ja kirjeldada arhiiviks/repositooriumiks, on selleks laialdaselt kasutusel tasuta rakendus DSpace. Andmete korrastamist ja kirjeldamist toetavad metainfosüsteemide rakendused ja andmehalduse tarkvarad. Neid on palju ning siin osutame üksnes mõnele. Statistikaamet juurutab metainfosüsteemiks rakendust Colectica. Mõned Eesti asutused on võtnud kasutusele andmekataloogi pidamist võimaldava Eesti tarkvara LiTech. Avaandmete, aga ka asutusesisesee andmehalduse (data management) jaoks on üks kasutatavamaid rakendusi CKAN, mis on ka tasuta.
KOKKUVÕTTEKS
Korrastatud ja kirjeldatud andmed, infovara, failid või sisu teeb vajaliku info kiiremini leitavaks, leitud teave on usaldusväärsem ja kindlamalt taaskasutatav.
Lõpus viidatud tarkvarad, olgu või tasuta saadaval, ei korrasta ega kirjelda sinu andmeid. Seega, hoidu korrastustegevuse asemel IT-projektiga tegelema hakkamast!
Täpsem teave:
Kai Kaljumäe
Kommunikatsioonipartner
statistika levi osakond
statistikaamet
tel +372 625 9184
press [at] stat.ee (press[at]stat[dot]ee)
Foto: Shutterstock